Cordiales Saludos
Entramos en una nueva etapa de nuestras publicaciones. Recordemos cuando abordamos el tema de Extract, Transform and Load / Extraer, Ttransformar y Cargar. En todas las publicaciones anteriores nos enfocamos en extraer los datos desde distintas fuentes y de diferentes formatos.
Con lo visto hasta ahora podemos trabajar con datos sin ningun problema. Aún quedan otras fuentes de datos que trataremos más adelante, como lo son: Consumo de Apis; trabajar con imágenes y texto; datos geoespaciales/mapas, extracción de datos de una Base de Datos, etc.
Hoy veremos los primeros comandos, creo que obligatorios, que siempre debemos hacer para cada nuevo proyecto.
Nos corresponde a partir de las próxímas publicaicones limpiar, organizar y transformar los datos.
Comencemos...
Los datos con que trabajaremos hoy los tomé del torneo de ajedrez CHECKMATE COIN ARENA de fecha 2022/01/24, que organizan @hive-129589, @giacomone y @petreius, todos los lunes.
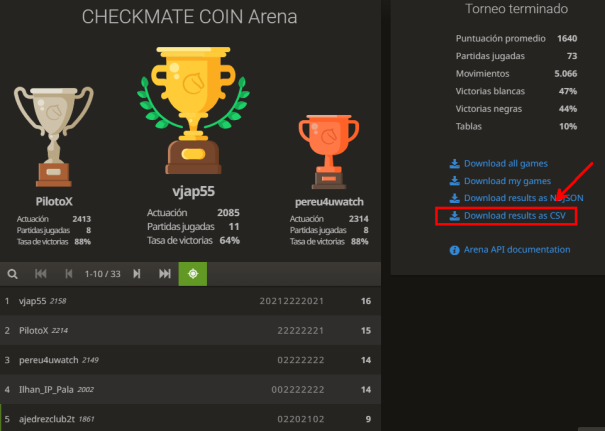 )
[Link]( https://lichess.org/tournament/RHb69yuT) de la tabla final del tornneo y de donde descargué el archivo.CSV
)
[Link]( https://lichess.org/tournament/RHb69yuT) de la tabla final del tornneo y de donde descargué el archivo.CSV
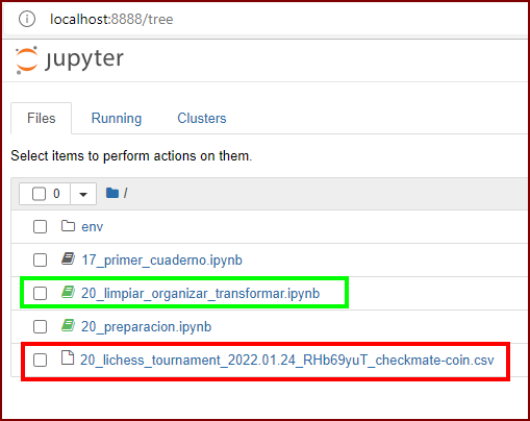
El archivo .csv debe estar en nuestro entorno virtual, usaré el que cree en la publicacion N017 (env) C:\hive_cuaderno>. El recuadro de color verde es el nombre del cuaderno y el recuadro rojo es el archivo .csv con que trabajaremos.
 )
)
Así se visualiza el archivo que acabamos de descargar
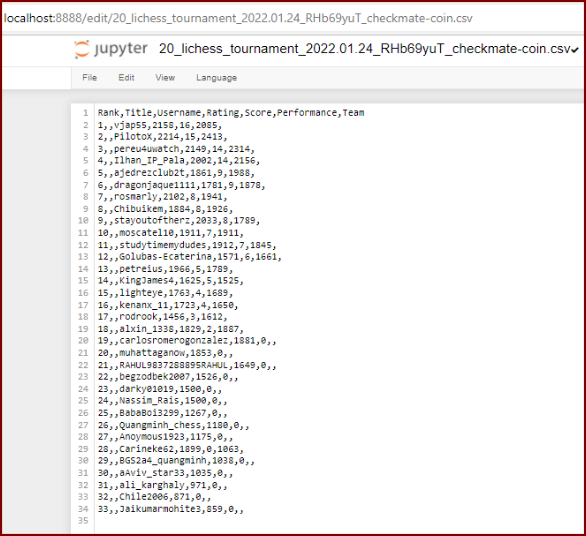 )
*Archivo: 20_lichess_tournament_2022.01.24_RHb69yuT_checkmate-coin.csv*
)
*Archivo: 20_lichess_tournament_2022.01.24_RHb69yuT_checkmate-coin.csv*
 )
)
Nuestras primeras instrucciones y sentencias
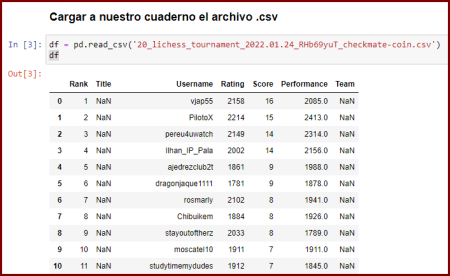
1.- Cargar los datos
En esta oportunidad cargamos un archivo con extensión .csv, ya vimos como hacerlo con hojas de cálculo(excel), Json y Html. Recuerden importar pandas!
import pandas as pd
df = pd.read_csv('20_lichess_tournament_2022.01.24_RHb69yuT_checkmate-coin.csv')
df
 )
)
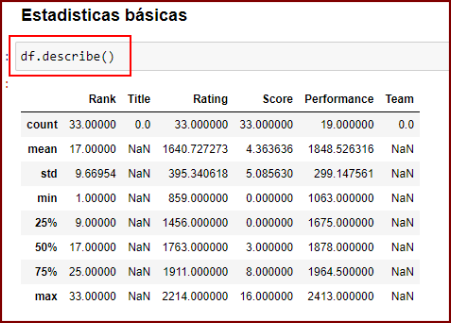
2.- Estadística Básica
Con df.describe() podemos ver datos básicos como el mayor valor, el menor, porcentajes básicos, etc. Nótese que solo muestra las columnas numéricas.
 )
)
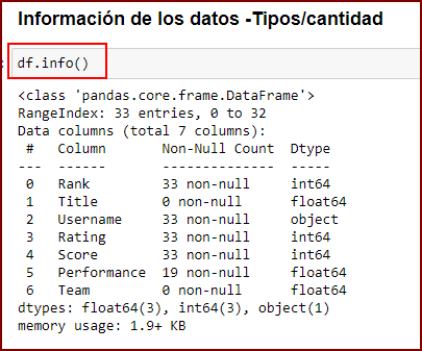
3.- Información de los datos que componen el DF
df.info() nos muestra de forma general los tipos de datos de las columna enteros, float o tipo objetos, además de los datos nulos.
 )
)
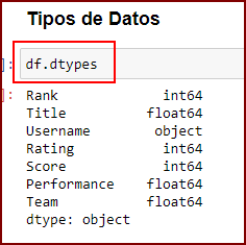
Aquí es más especifico el tipo de datos de cada columna. Usamos: df.dtypes
 )
)
 )
)
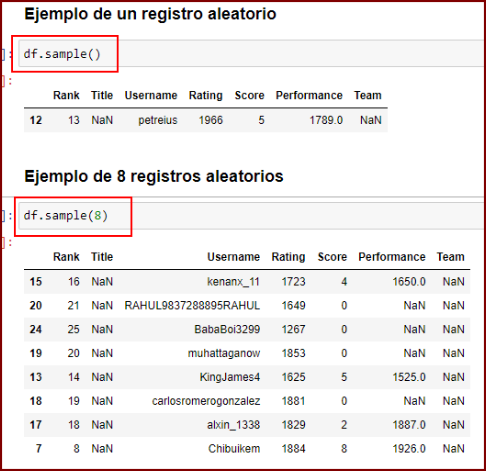 )
)
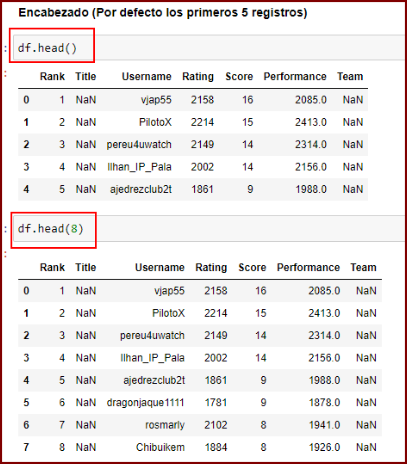 )
)
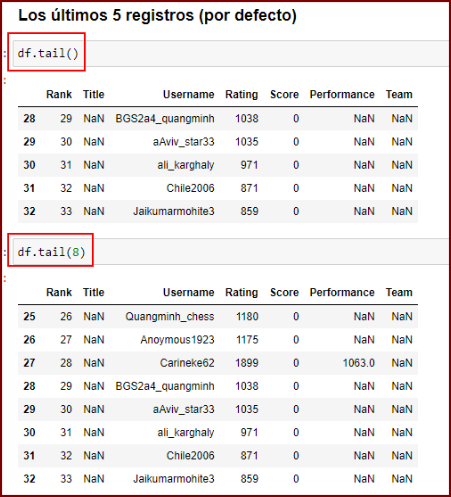 )
)
9.- Quitar el índice automático
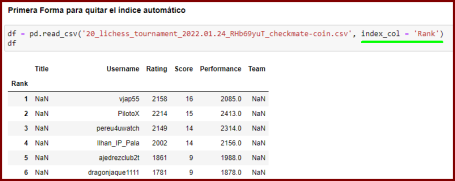
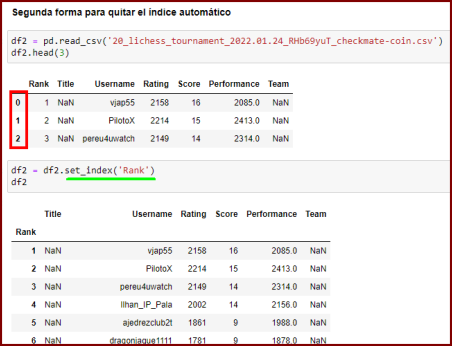
Para ello tenemos dos formas de hacerlo. Observemos que cuando llamamos el archivo .csv (línea verde) se crea automáticamente un indice que comienza en cero (recuadro rojo).
Como ya la tabla tiene su propio índice Rank, debemos eliminar el que se creó automaticamente. A veces nos combiene dejar este índice que se generó.
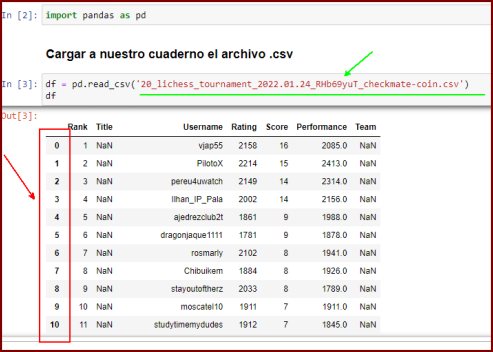 )
)
Primera forma: Con agregar index_col = 'Rank' como argumento adicional es suficiente (línea verde).
 )
)
 )
)
Ver el Cuaderno completo con los ejercicios en mi repositorio de Github
)
Aquí concluyo esta antesala a limpiar, organizar y transformar los datos. Vimos las primeras instrucciones que pueden variar en orden después de haber cargado el archivo .csv. Son muy sencillas y fáciles de aprender, con solo practicarlas!. No subestimes estas instrucciones, su potencialidad la notarás cuando trabajes con archivos con cientos de columnas y cientos de registros.
Links de interes:
)
Para quienes terminaron el Curso Gratis de Programación con python y para todos los interesados, ordené todas las publicaciones dedicadas a Data Science realizadas aquí en @hive, en una página web, para que tengan fácil acceso a cada entrada. La dirección es Python Cumanés (Data Science) y aquí la dirección de pythoncumanes Una vez más los invito a practicar, practicar, practicar... Hasta la próxima entrega, Feliz Día!
 )
)
 )
)
)
)
Invitación Especial
Apreciada comunidad extiendo mi invitación, para todos los que hacemos vida en esta maravillosa comunidad, a participar con la etiqueta #Hive para promocionar nuestras publicaciones en la red social: #Twitter. Para más detalles puedes consultar la publicación de @hive-data
 )
[*Fuente:*](https://peakd.com/hive-167922/@hiro-hive/hive-promotional-materials-for-graphics-images-gifs-and-videos-are-ready-to-use)
)
)
[*Fuente:*](https://peakd.com/hive-167922/@hiro-hive/hive-promotional-materials-for-graphics-images-gifs-and-videos-are-ready-to-use)
)
Clases gratis de programación / Free programming classes
)
Todos a programar!
[Rafael Aquino](https://www.facebook.com/rafael.aquino.5815)
Comments (5)
Great post, congratulations!
Thanks to you for reading
https://twitter.com/Rafa_elaquino/status/1488666445907218434 The rewards earned on this comment will go directly to the person sharing the post on Twitter as long as they are registered with @poshtoken. Sign up at https://hiveposh.com.
¡Enhorabuena!
✅ Has hecho un trabajo de calidad, por lo cual tu publicación ha sido valorada y ha recibido el apoyo de parte de CHESS BROTHERS ♔ 💪
♟ Te invitamos a usar nuestra etiqueta #chessbrothers y a que aprendas más sobre nosotros.
♟♟ También puedes contactarnos en nuestro servidor de Discord y promocionar allí tus publicaciones.
♟♟♟ Considera unirte a nuestro trail de curación para que trabajemos en equipo y recibas recompensas automáticamente.
♞♟ Echa un vistazo a nuestra cuenta @chessbrotherspro para que te informes sobre el proceso de curación llevado a diario por nuestro equipo.
Cordialmente
El equipo de CHESS BROTHERS
Gracias por el apoyo!
@rafaelaquino Very interesting!
I am now studying data science and it is really interesting!
Thank you, very useful post ❤️
Thank you for taking the time to review my publication